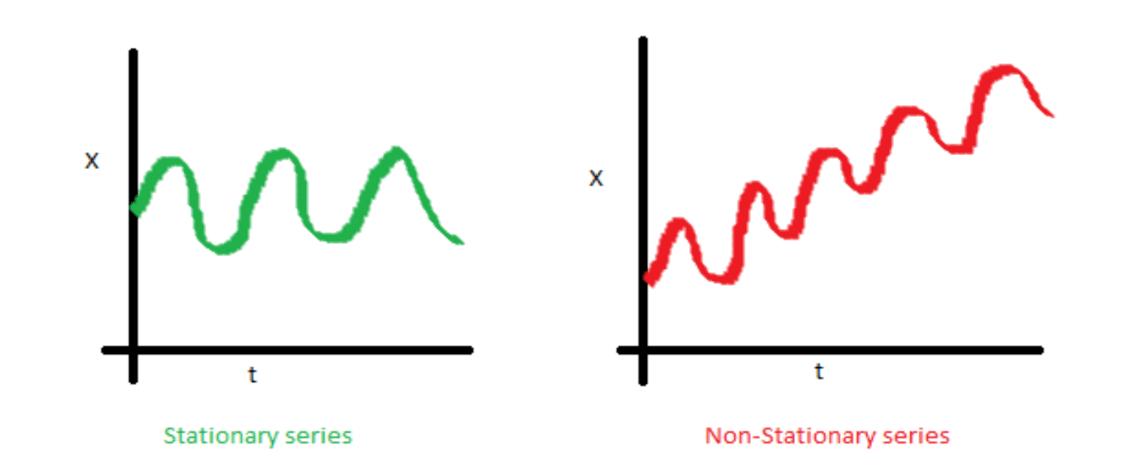
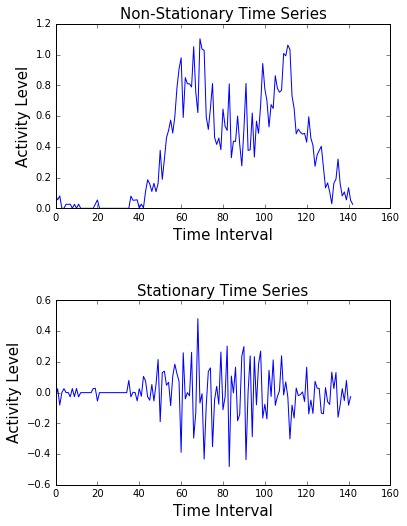
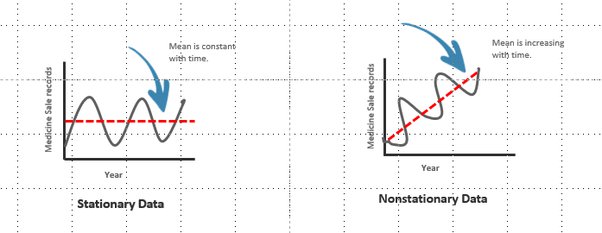
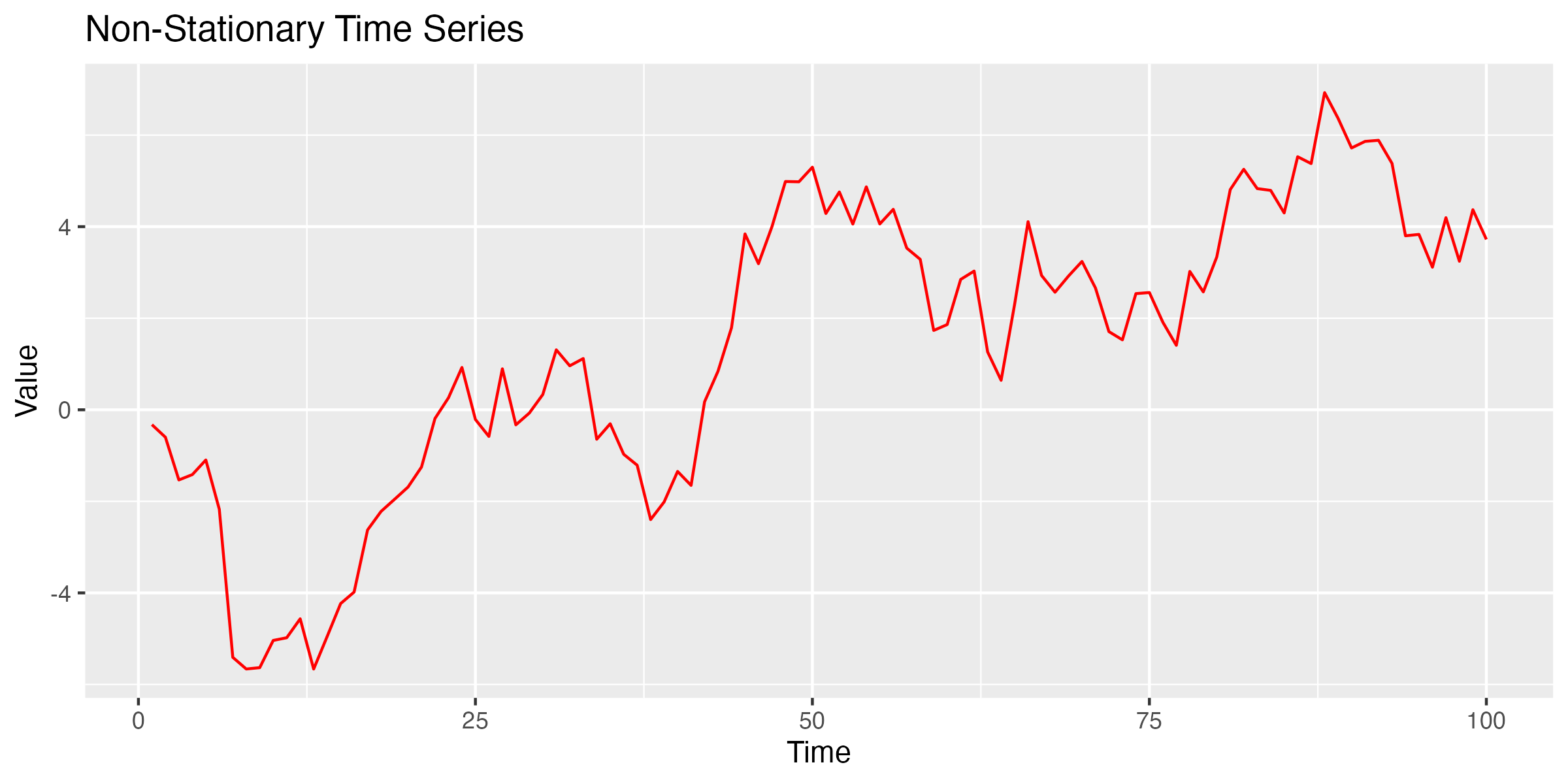
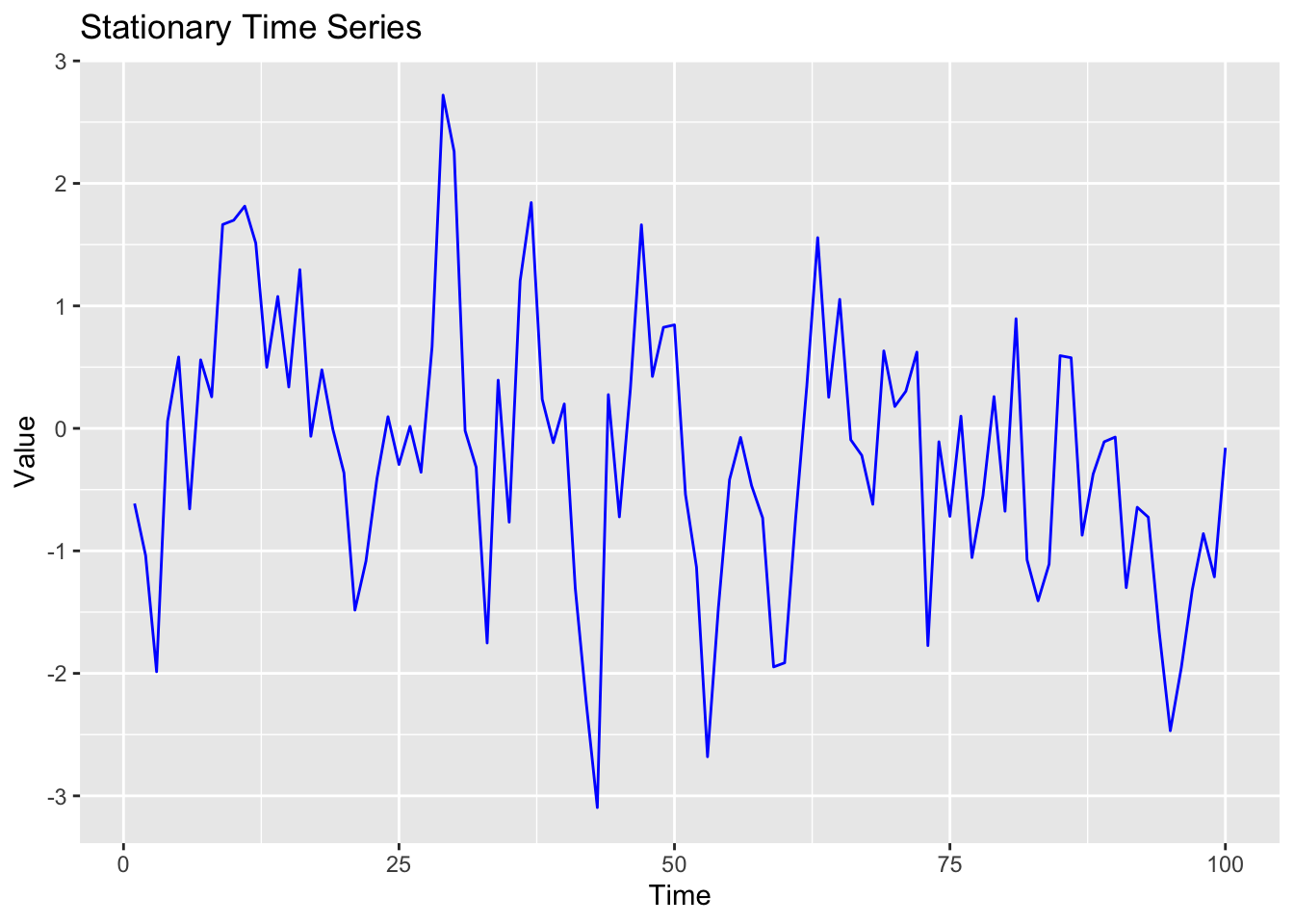
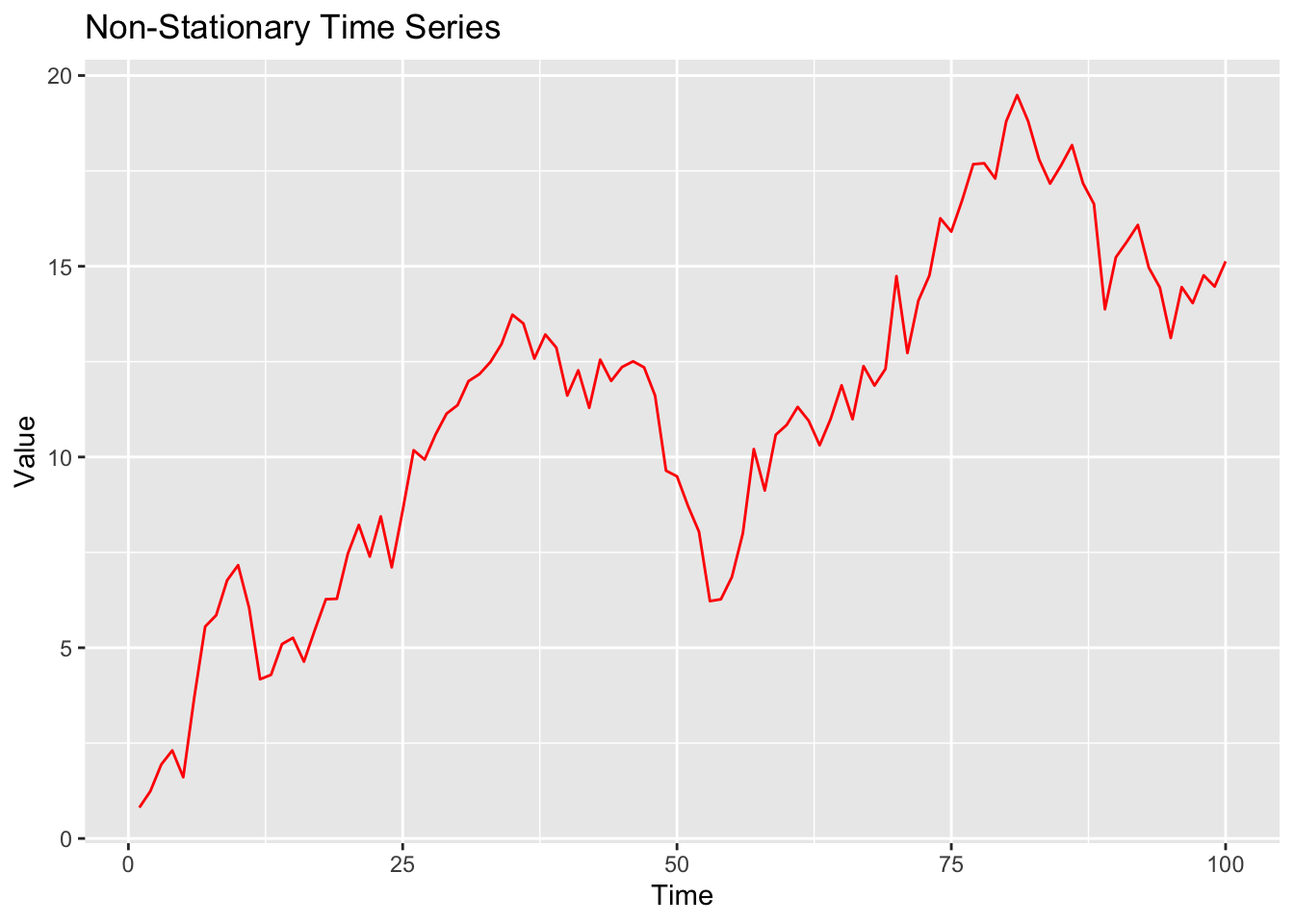
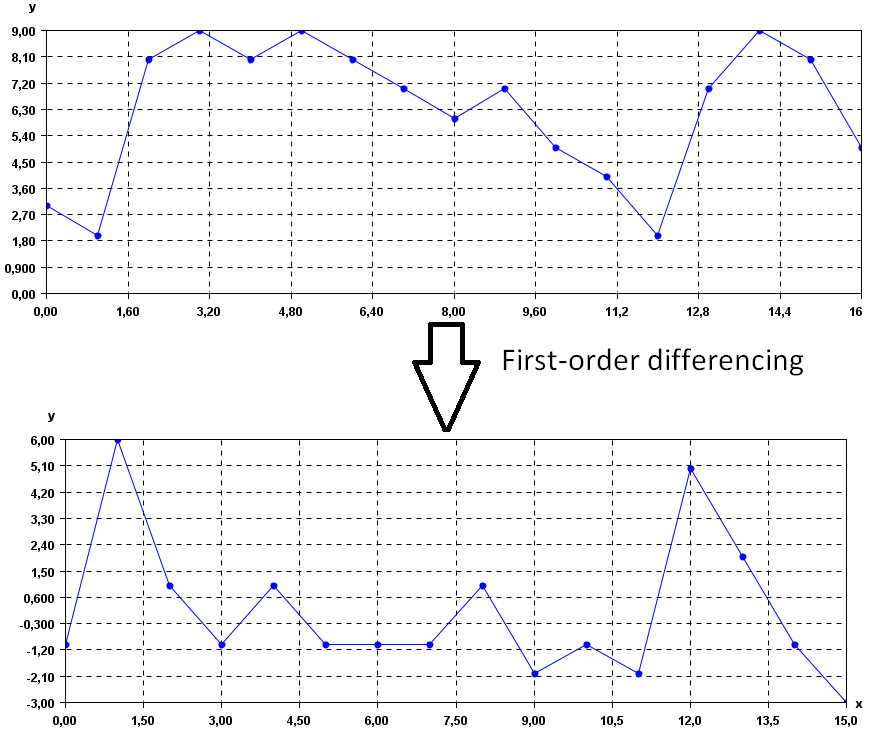
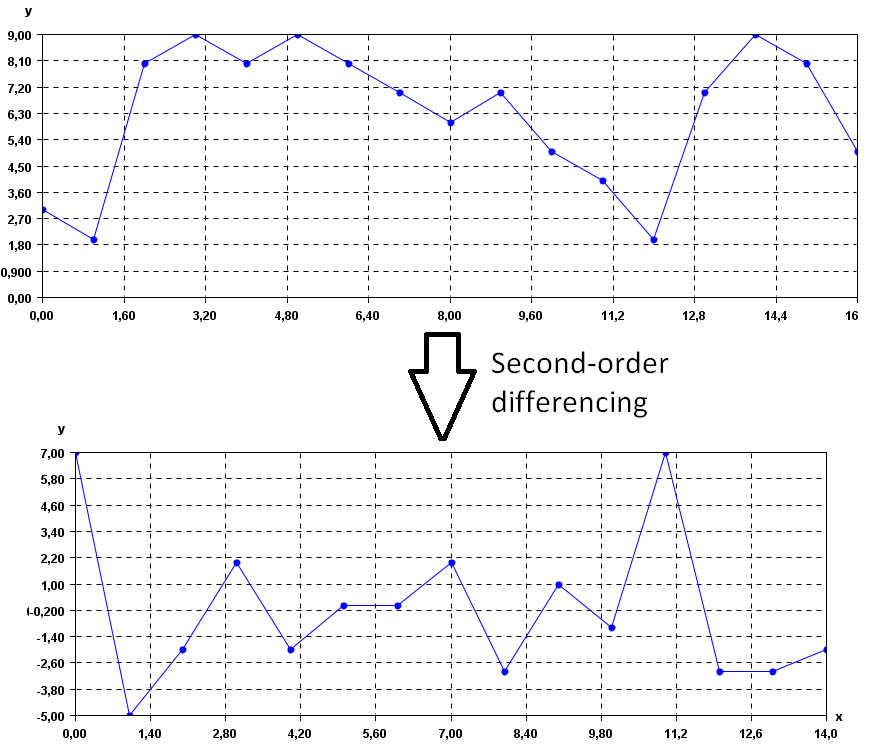
Imaginer you’re looking at the money you save each week. Some weeks you save a little, like £10, and other weeks a lot more, like £100 or £1000. This wide range of values can make it hard to see patterns or trends in your savings behaviour.
By applying a log transformation, you’re essentially ‘squishing’ this wide range of values into a narrower, more manageable scale. When you take the logarithm of your savings, smaller amounts and larger amounts get closer together in value.
For instance, the logarithm (usually base 10 is used) of £10 is 1, of £100 is 2, and of £1000 is 3. Now, instead of dealing with £10, £100, and £1000, you’re dealing with 1, 2, and 3, which are easier to compare and analyse.